Unleashing the Power of Random Forest Classification: A Practical Guide
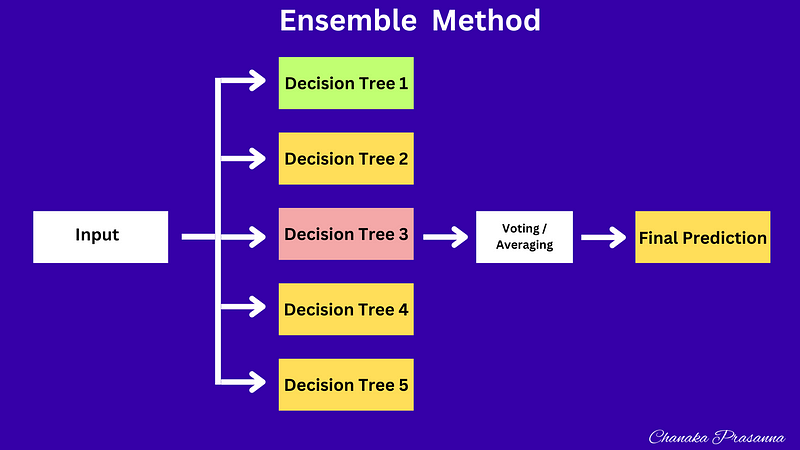
Random Forest is a well-known supervised machine learning algorithm used with labeled data, and it falls under the ensemble learning…
Random Forest is a well-known supervised machine learning algorithm used with labeled data, and it falls under the ensemble learning technique, which involves combining predictions from multiple decision trees to enhance performance. It can be applied to both classification and regression problems.
How does Random Forest Classification work?
Imagine a scenario where you encounter a highly complex problem in your workplace that you’re unable to solve on your own. In this situation, you decide to seek assistance from experts in the field. You describe the problem to the team, and they initiate the problem-solving process. Since team members may have varying ideas and perspectives on the matter, how do they arrive at a solution?
Team members share their insights and opinions, drawing from their wealth of experience and expertise. Subsequently, they engage in a voting process to reach a final decision, opting for the solution that garners the most votes. This same fundamental process mirrors the workings of the Random Forest Classification algorithm.
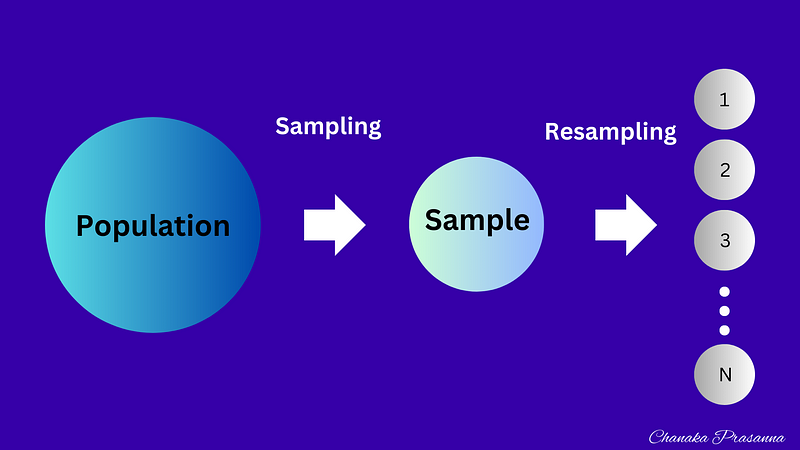
In random forest classification, every resample generates a decision tree and provides predictions about the data. Subsequently, the algorithm selects the outcome that proves to be the most popular among the trees. In the case of regression problems, predictions are determined using an averaging technique instead.
Let’s take a look at a sample implementation of a Random Forest classifier using Python. Below, you’ll find the code to be executed in a Jupyter notebook
Then, we load a dataset called ‘heart-disease.csv’ using pandas and store it in a variable named ‘heart_disease’.
Click here to download the data set
import pandas as pd
import numpy as np
heart_disease = pd.read_csv('data/heart-disease.csv')
heart_disease.head()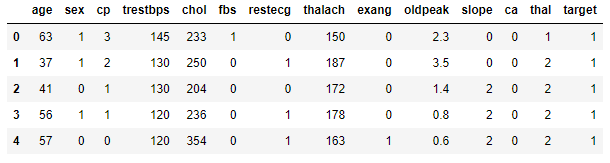
heart_disease.head()=> Provide top 5 data records
2. Now we divide our data set into X and y.
X (Feature Matrix): This part includes all the features or attributes that will be used to make predictions. It consists of various characteristics of the patients (e.g., age, sex, cholesterol levels, etc.) and does not include the “target” column. Each row in this matrix represents a patient.
y (Labels): This part represents the target values or labels you want to predict. In the context of heart disease classification, “target” is typically a binary variable where 1 indicates that a patient has heart disease, and 0 indicates that a patient does not have heart disease. Each value in the “y” array corresponds to a patient’s heart disease status.
# Create X (Feature matrix) without target column
X = heart_disease.drop("target",axis = 1)
#Create Y (Labels)
y = heart_disease["target"]The axis parameter is used in the drop method to specify whether you are dropping a row (axis=0) or a column (axis=1).
3. Import the RandomForestClassifier and create an instance
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier()from sklearn.ensemble import RandomForestClassifier: This line imports the RandomForestClassifier from the Scikit-Learn library, making it available for use in your Python script.
clf = RandomForestClassifier(): It creates an instance of the RandomForestClassifier and assigns it to the variable clf. This instance will be used to build a classification model using the Random Forest algorithm.
4. We will now split the data into training and test sets.
In this split, 80% of the data will be used for training the model, while the remaining 20% (test_size=0.2) will be reserved for testing its performance.
from sklearn.model_selection import train_test_split
np.random.seed(42)
X_train,X_test, y_train, y_test = train_test_split(X,y, test_size=0.2)Reproducibility: By setting the random seed to a specific value (in this case, 42), you ensure that any random processes, such as random data splitting or initialization of random model parameters, will produce the same results every time you run the code. This is essential for reproducibility in research or when sharing your code with others.
5. Then find the pattern in the training data using the instance of the Random Forest classifier.
clf.fit(X_train,y_train)6. Making Data Predictions
After utilizing the classifier ‘clf’ to make predictions on the test data ‘X_test,’ we obtain the predictions
y_preds = clf.predict(X_test).
y_preds7. Evaluate the model on the training data
It assesses how well the model performs on the training data
clf.score(X_train,y_train)Output — 1.0
8. Evaluate the model on the test data
It gauges the model’s performance on unseen data, helping to assess its generalization capabilities
clf.score(X_test,y_test)Output — 0.8524590163934426
In addition to the discussed metrics, it’s worth noting that scikit-learn provides a range of other evaluation tools for assessing model performance. These include the classification_report, confusion_matrix, and accuracy_score, each offering unique insights into the model's accuracy, precision, and ability to handle different classes.
In conclusion, the Random Forest algorithm is a powerful tool in machine learning for both classification and regression tasks. Its ability to harness the collective wisdom of multiple decision trees and make predictions based on voting or averaging results in robust and accurate models. In this blog post, we’ve walked through a sample implementation of a Random Forest classifier, showcasing the essential steps, from data preprocessing to model evaluation. By understanding and effectively utilizing this algorithm, data scientists and analysts can tackle complex problems and make reliable predictions, contributing to informed decision-making and improved outcomes in various domains.