Steps For Your Machine Learning Project
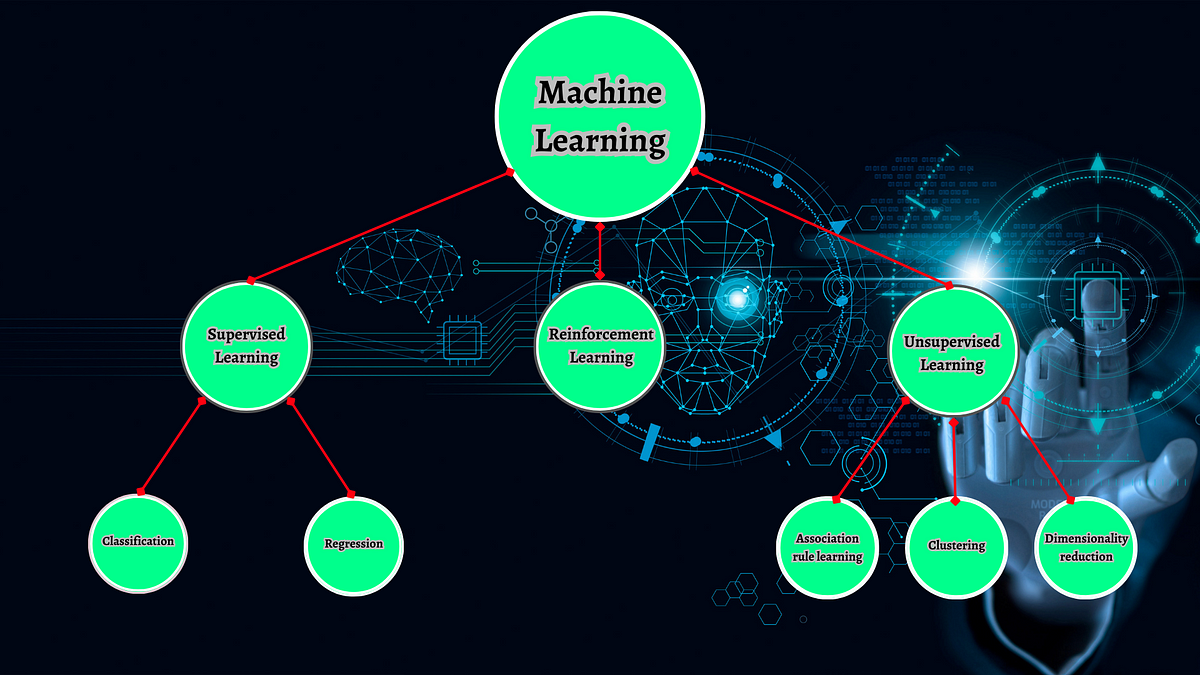
Before embarking on a machine learning project, it’s crucial to grasp the fundamental classifications of machine learning: supervised…

Before embarking on a machine learning project, it’s crucial to grasp the fundamental classifications of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Data and labels are available in supervised learning, whereas unsupervised learning deals with unlabeled data. Reinforcement learning comes into play when explicitly defining desired behavior, such as determining how a self-driving car should navigate various traffic scenarios.
Step 1: Problem Definition
The first step involves discerning the problem’s nature. Is it conducive to supervised learning, unsupervised learning, or reinforcement learning? Should the problem align with supervised learning, the subsequent step revolves around delineating the precise subtype within supervised learning, which can either be classification or regression, depending on the nature of the task. For unsupervised learning, the focus shifts to uncovering patterns and structures without labeled guidance. In the realm of reinforcement learning, it entails defining desired behaviors in scenarios where explicit specifications are challenging. Each problem type warrants tailored approaches and methodologies to achieve optimal results.
Step 2: Identifying Your Data
Identify the nature of the data you’re working with. Data can be categorized into various types, such as structured (with rows and columns), unstructured (including images and audio), static (unchanging over time), or streaming (constantly evolving). Understanding your data’s characteristics is key to effective model development.
Step 3: Evaluation Metrics
When assessing your model’s performance, the choice of metrics depends on the type of problem you’re addressing. For classification tasks, pivotal metrics include accuracy, precision, and recall, offering insights into correct classifications, false positives, and false negatives, respectively. The F1-Score strikes a balance between precision and recall, while the ROC Curve and AUC provide a holistic view of binary classification performance. In regression tasks, you’ll commonly employ metrics like Mean Absolute Error (MAE), Mean Squared Error (MSE), Root Mean Squared Error (RMSE), and R-squared to gauge prediction accuracy. In cases involving imbalanced datasets, F1-Scores (weighted or macro) and Area Under the Precision-Recall Curve (AUC-PR) may be preferred. Multi-class classification benefits from metrics such as multi-class accuracy and Cohen’s Kappa, and time-series forecasting relies on Mean Absolute Percentage Error (MAPE) and autocorrelation functions (ACF and PACF). Choosing the right mix of these metrics ensures a comprehensive evaluation tailored to your project’s objectives and data characteristics
Step 4: Features in Data
Investigate the features present in your dataset. Identify whether they are numerical or categorical, as this knowledge informs your modeling approach.
Step 5: Model Selection and Training
Selecting the optimal model for your machine learning project is a critical decision. To make the right choice, start by considering the problem’s characteristics and goals. Assess the dataset size, complexity, and distribution. Experiment with various algorithms and techniques, adjusting hyperparameters as needed. Employ cross-validation to evaluate each model’s performance and avoid overfitting or underfitting. Pay attention to evaluation metrics relevant to your task, seeking a balance between precision and recall, accuracy, or other suitable criteria. Additionally, consider the model’s interpretability and computational requirements. Finally, leverage domain expertise and prior experience to guide your selection, ensuring that the chosen model aligns with both the data and the project’s objectives.
The modeling process involves three critical stages:
- Choosing and training a model.
- Tuning the model.
- Comparing models.
Partition your dataset into three subsets: a training set (70%-80% of the data), an evaluation set (10%-15%), and a testing set (10%-15%). Striking the right balance is crucial, as using a too-simplistic model may lead to underfitting, whereas an overly complex model risks overfitting. To mitigate underfitting, consider employing a more advanced model, adjusting hyperparameters, reducing features, or extending training time. To combat overfitting, gather more data or opt for a simpler model.
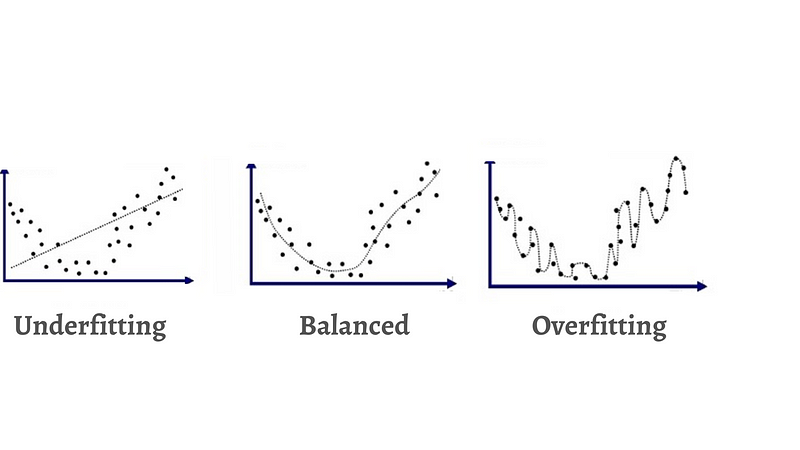
Step 6: Generalization and Experimentation
The ultimate goal of your machine learning model is to generalize well to unseen data. Ensure your model’s ability to perform on new, unencountered data (generalization). Experimentation is key to model improvement. Constantly explore ways to enhance your model’s performance and consider what steps to take next in your machine-learning journey.