Cross Validation Explained - Leave One Out, K Fold, Stratified, and Time Series Cross Validation Techniques


Cross-validation is a technique for evaluating machine learning models by training them on different subsets of the available data and testing them on the remaining data. This approach helps to detect overfitting, which occurs when a model performs well on training data but fails to generalize to new, unseen data.
Simple Example of Cross-Validation
Let’s say you have a dataset with 100 records, and you want to evaluate a model using cross-validation. Here’s a straightforward way to understand how it works.
- Divide the 100 records into 5 equal parts, each with 20 records.
- For each of the 5 iterations:
- Use 4 parts (80 records) to train the model.
- Test the model on the remaining part (20 records).
- Do this 5 times, so each of the 5 parts gets a chance to be the test set once.
- After completing all 5 iterations, you average the performance metrics (like accuracy) across the 5 test sets.
By using this method, you ensure that every record in your dataset is used for both training and testing, providing a more reliable estimate of how well your model performs on unseen data.
In cross-validation, we do something similar with our data
- Split Data - We split our dataset into several smaller parts.
- Train and Test - We train our model on some of these parts (training data) and test it on the remaining parts (testing data).
- Repeat - We repeat this process several times, each time using different parts of the data for training and testing.
- Average Performance - Finally, we average the results from all the tests to get a more reliable estimate of how well our model performs.
Why Cross-Validation Helps
Cross-validation is essential for several key reasons
1. Accurate Performance Estimation
Cross-validation offers a more reliable estimate of how a model will perform on new data. By testing the model on multiple data subsets, you avoid overestimating its performance based on just one train-test split.Testing a model once might give misleading results, but averaging performance across multiple folds provides a clearer picture.
2. Reduces Overfitting
It helps prevent overfitting by ensuring the model is validated on data it hasn’t seen during training. This means the model learns to generalize better rather than memorizing the training data.Training and testing on different data subsets ensures the model isn't just memorizing but learning general patterns.
3. Efficient Data Use
Cross-validation makes the most out of available data. Each data point is used for both training and testing, maximizing the dataset's utility.Instead of setting aside a large portion of data as a test set, cross-validation uses every data point for both training and evaluation.
4. Improves Model Selection
It helps in choosing the best model or configuration by comparing performance across different parts of data. This ensures the model that consistently performs well is selected.Comparing models using cross-validation helps in identifying which model has the most reliable performance.
5. Detects Performance Variability
Cross-validation reveals how a model's performance varies with different data subsets, indicating its stability and robustness.A model with consistent performance across folds is more reliable, while significant variability may signal overfitting or instability.
Types of Cross-Validation
Leave-One-Out Cross-Validation (LOOCV)
It involves using each individual data point as a test set once while using the remaining data points to train the model. The main advantage of LOOCV is that it provides a thorough evaluation of the model’s performance, as every data point is used for testing. However, it can be computationally expensive, especially with larger datasets, because the model needs to be trained as many times as there are data points.
Assume you have 10 data records. You take 1 data point (let’s take the first data point) as the test data and use the remaining 9 records for training the model. Then, you use the second data point as the test data and the remaining 9 records as the training data. This process continues 10 times, with each data point being used as the test data once. The below image shows only the first 4 instances of the process.

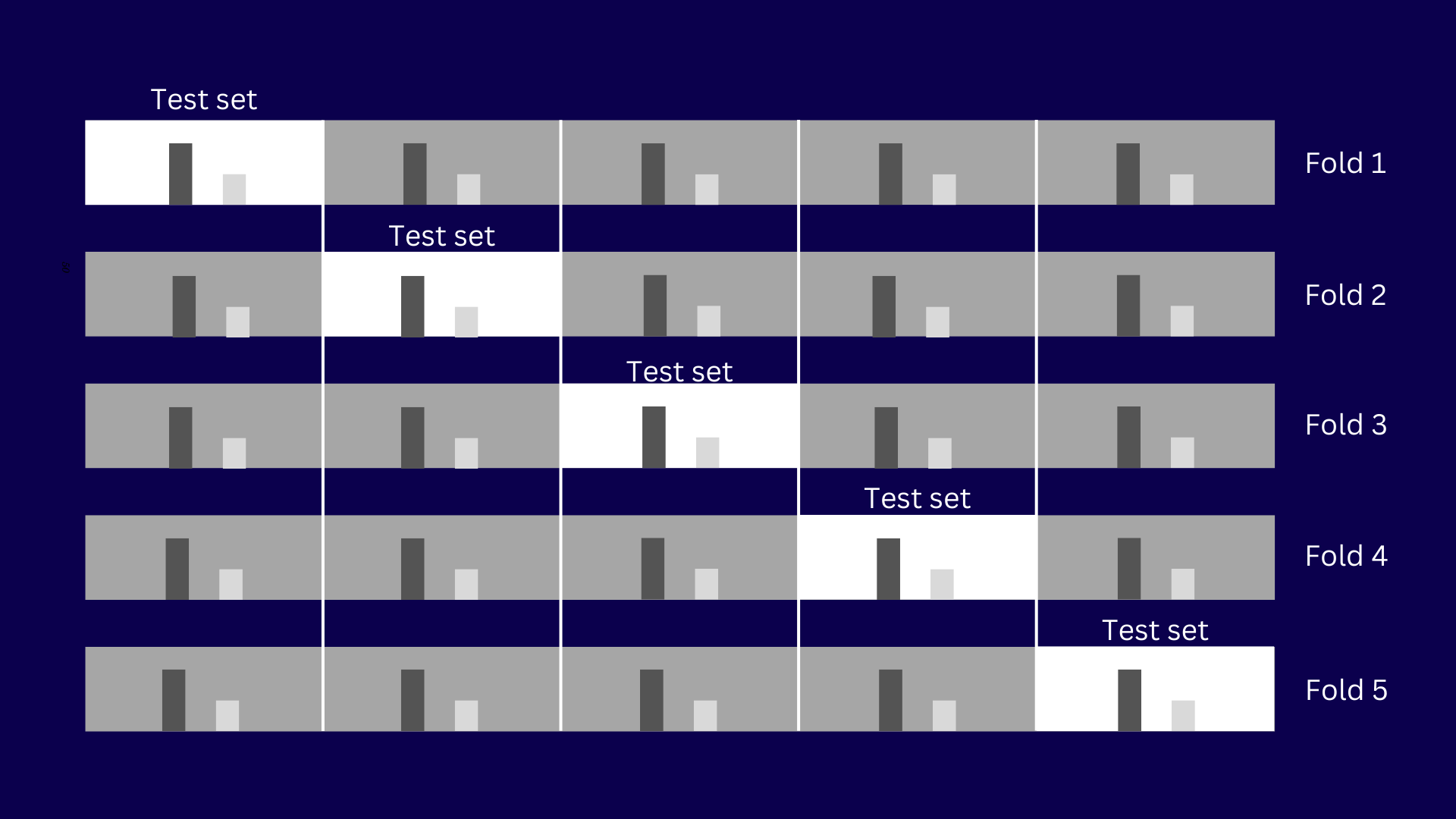
K-Fold Cross-Validation
It divides the dataset into K equally-sized parts, known as folds. The model is trained on K-1 of these folds and tested on the remaining fold (1 part of 5 set). This process is repeated K times, with each of the K folds being used as the test set once. K-Fold Cross-Validation strikes a balance between computational efficiency and a reliable performance estimate. The choice of K can affect the performance estimate, with common choices being 5 or 10.
For instance, with 5-fold cross-validation, the data is split into 5 parts. The model is trained and evaluated 5 times, each time using a different fold as the test set.

Stratified Cross-Validation
It is similar to K-Fold Cross-Validation but is specifically designed to handle imbalanced datasets. In this method, each fold is created so that it reflects the overall distribution of classes in the dataset. This approach ensures that each fold is representative of the whole dataset, which is particularly important for datasets where some classes are underrepresented. Stratified Cross-Validation provides a more consistent and fair evaluation of the model's performance on imbalanced data.
For instance, if 10% of your data belongs to one class and 90% to another, each fold will maintain this ratio. In the example image, you can see that each fold contains both classes and preserves the original ratio of the dataset for each class.
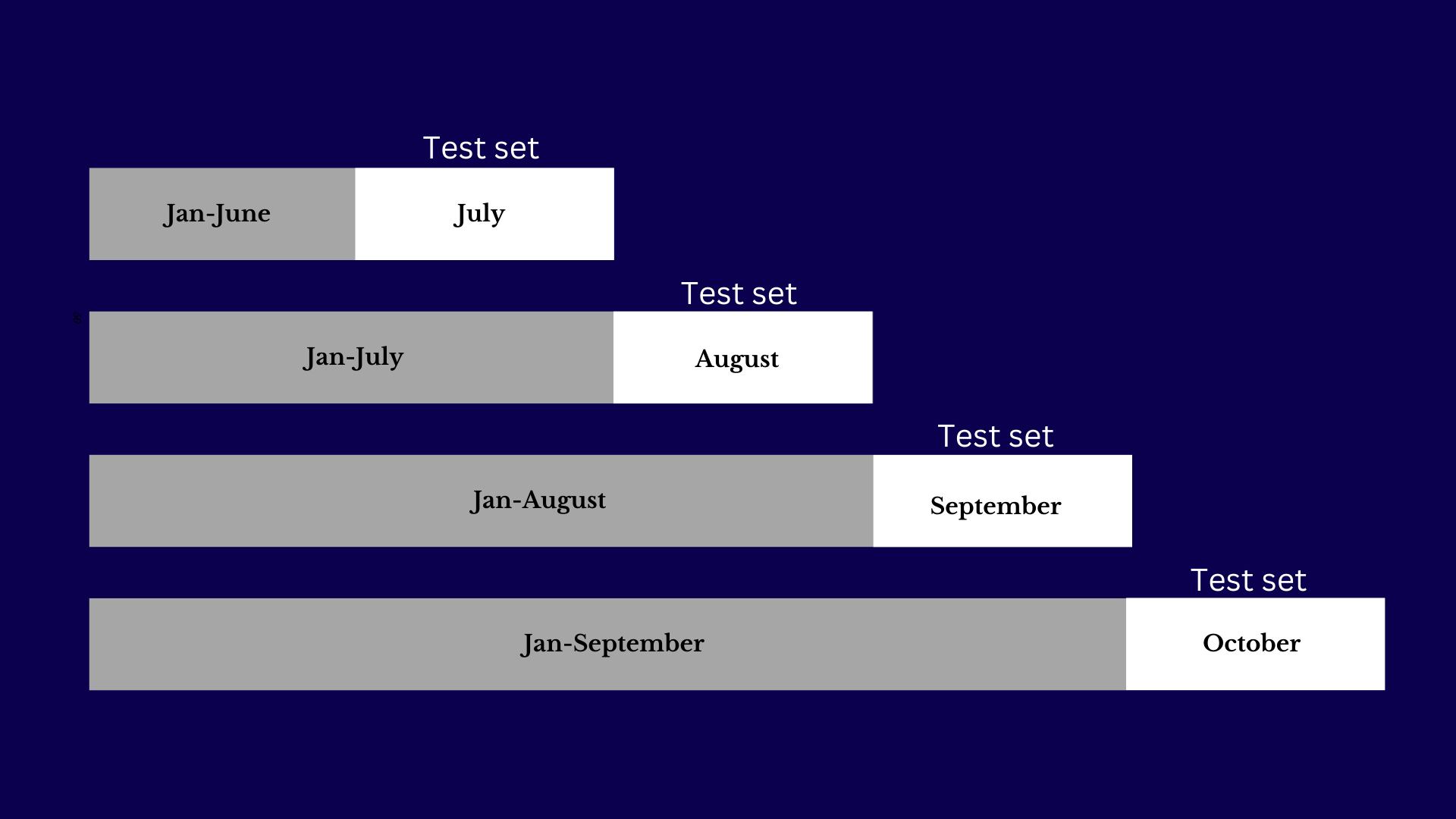
Time Series Cross-Validation
It is used for datasets where the order of data points is crucial, such as in time series forecasting. This method involves splitting the data in a way that respects the chronological order. The model is trained on past data and tested on future data, which reflects real-world scenarios where predictions are made based on historical information. Time Series Cross-Validation ensures that the model is evaluated in a manner that aligns with the temporal nature of the data.
For instance, you might train the model on data from January to June and test it on data from July. Then, you might train on data from January to July and test on August data.
Each of these cross-validation techniques helps ensure that the model’s performance is accurately assessed and that it can generalize well to new data. The choice of method depends on the characteristics of the dataset and the specific requirements of the model evaluation.
Cross-validation is a powerful technique for evaluating machine learning models, ensuring that they perform well across different subsets of data and generalize effectively to new, unseen data. By dividing your data into multiple folds and iteratively training and testing your model, you gain a more reliable assessment of its performance and reduce the risk of overfitting. Whether using k-fold, leave-one-out, or other methods, cross-validation helps you make informed decisions about model selection and improvement, ultimately leading to more robust and accurate predictive models.
If you found this article helpful follow me on LinkedIn.