Converting Categorical Data into Numerical Form in Machine Learning


Categorical data refers to variables that represent categories or labels rather than numerical values. For example, "color" could have categories like "red," "blue," and "green." Machine learning algorithms, however, typically require numerical input to perform computations. Converting categorical data into numerical form allows these algorithms to process and learn from the data.
Why Is It Important?
- Algorithm Requirements - Most machine learning algorithms, like regression, SVM, and neural networks, require numerical input. Categorical data must be transformed to fit these algorithms.
- Data Consistency - Numerical data can be processed more consistently and efficiently by algorithms compared to categorical data.
- Performance - Properly transforming categorical data can improve the performance and accuracy of machine learning models.
3 Ways to Convert Categorical Data
Here are several methods for transforming categorical data into numerical format, demonstrated using synthetic dataset.
Download the full notebook here
Code for generating the dataset
import pandas as pd
import numpy as np
# Set random seed for reproducibility
np.random.seed(42)
# Define sample data
num_records = 1000
# Generate random categorical data
colors = np.random.choice(['red', 'blue', 'green', 'yellow'], num_records)
sizes = np.random.choice(['small', 'medium', 'large'], num_records)
categories = np.random.choice(['A', 'B', 'C'], num_records)
# Generate random numerical data
values = np.random.randn(num_records) * 10
# Create DataFrame
df = pd.DataFrame({
'color': colors,
'size': sizes,
'category': categories,
'value': values
})
print(df.head())
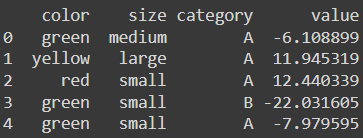
Let's understand each way using examples
1. Label Encoding
LabelEncoder is a tool in machine learning used to convert categorical labels into numeric values. It encodes target labels with value between 0 and n_classes-1 Imagine you have a list of categories like "apple," "banana," and "cherry." Instead of working with these text labels directly, LabelEncoder transforms them into numbers: for example, "apple" might become 0, "banana" 1, and "cherry" 2. This is helpful for algorithms that work better with numbers than with text.
There we can see some important methods like fit fit_transform and inverse_transform . Let's understand each method.
fit
What it does - The fit method learns the unique categories in the data. This method prepares the LabelEncoder for transforming data.
from sklearn.preprocessing import LabelEncoder
# Initialize LabelEncoder
le_encoder = LabelEncoder()
# Fit the encoder on the 'color' column
le_encoder.fit(df['color'])
# Print the classes learned by the encoder
print("Classes:", le_encoder.classes_)
Output —> Classes: ['blue' 'green' 'red' 'yellow']
Simply, in the fit method, it identified available classes (Color variants) for color feature
fit_transform
What it does - The fit_transform method performs both fit and transform in one step. It learns the unique categories and then converts them into numeric values.
# Initialize separate LabelEncoder instances
le_color = LabelEncoder()
le_size = LabelEncoder()
le_category = LabelEncoder()
# Fit and transform the 'color', 'size', and 'category' columns
df['color_encoded'] = le_color.fit_transform(df['color'])
df['size_encoded'] = le_size.fit_transform(df['size'])
df['category_encoded'] = le_category.fit_transform(df['category'])
print(df.head())
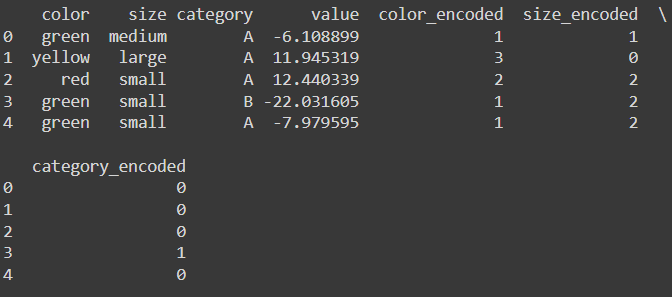
Now you can see three new columns with numerical values.
inverse_transform
What it does - The inverse_transform method converts numeric values back into the original categorical labels.
# Convert the encoded 'color' values back to the original labels
original_colors = le_color.inverse_transform(df['color_encoded'])
original_sizes = le_size.inverse_transform(df['size_encoded'])
original_categories = le_category.inverse_transform(df['category_encoded'])
print(original_colors[:5]) # Display first 5 original labels
print(original_sizes[:5])
print(original_categories[:5])

Now, we have returned our original data. (Here the first 5 records only)
2. One-Hot Encoding
OneHotEncoder is a tool used to convert categorical features into a one-hot numeric array. This means that for each category in your data, it creates a new binary column (0 or 1) indicating the presence or absence of that category.
For example, if you have a feature called color with values like 'red', 'blue', and 'green', OneHotEncoder will create three new columns: color_red, color_blue, and color_green. If an entry is 'red', the encoder will set color_red to 1 and the others to 0.
- Input - The input should be an array-like structure of categorical values (either integers or strings).
- Output - The output is a binary matrix or array where each column represents a category.
- Categories - By default,
OneHotEncoderautomatically determines the categories based on the unique values in the data. You can also specify the categories manually if needed.
Here also you can have fit, fit_transform, and inverse_transform like methods. Read and give it a try. I will cover three methods that I mentioned here. You need to recreate the data frame to see the outputs below.
fit
What it does - The fit method learns the unique categories from the data. It prepares the OneHotEncoder to transform the data by identifying which categories exist and how many binary columns will be created.
# Create DataFrame
df = pd.DataFrame({
'color': colors,
'size': sizes,
'category': categories,
'value': values
})
from sklearn.preprocessing import OneHotEncoder
# Initialize OneHotEncoder
ohe = OneHotEncoder(sparse_output=False,drop='first') # Set sparse_output=False for a dense array
# Fit the encoder on the 'color' column
ohe.fit(df[['color']])
# Print the categories learned by the encoder
print("Categories:", ohe.categories_)
Output —> Categories: [array(['blue', 'green', 'red', 'yellow'], dtype=object)]
It identified available variants for the color column.
fit_transform
What it does - The fit_transform method performs both fit and transform in one step. It learns the unique categories and then converts them into one-hot encoded binary columns.
Let's apply it for all categorical columns and make a new data frame. Here you need to create 3 encoders for each column.
# Initialize OneHotEncoders
ohe_color = OneHotEncoder(sparse_output=False,drop='first')
ohe_size = OneHotEncoder(sparse_output=False,drop='first')
ohe_category = OneHotEncoder(sparse_output=False,drop='first')
# Fit and transform the 'color' column
color_encoded = ohe_color.fit_transform(df[['color']])
color_encoded_df = pd.DataFrame(color_encoded, columns=ohe_color.get_feature_names_out(['color']))
# Fit and transform the 'size' column
size_encoded = ohe_size.fit_transform(df[['size']])
size_encoded_df = pd.DataFrame(size_encoded, columns=ohe_size.get_feature_names_out(['size']))
# Fit and transform the 'category' column
category_encoded = ohe_category.fit_transform(df[['category']])
category_encoded_df = pd.DataFrame(category_encoded, columns=ohe_category.get_feature_names_out(['category']))
# Combine the encoded columns with the original DataFrame (excluding original categorical columns)
encoded_df = pd.concat([color_encoded_df, size_encoded_df, category_encoded_df, df[['value']].reset_index(drop=True)], axis=1)
print(encoded_df.head())
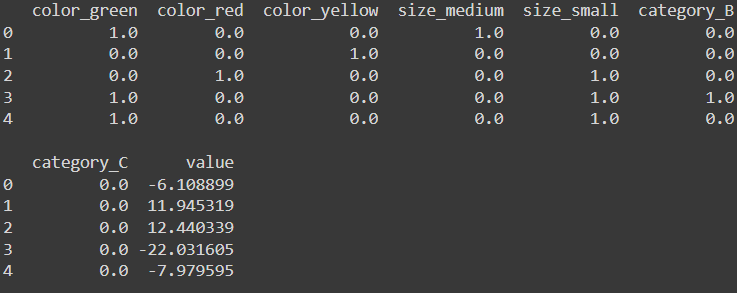
Here I fit the encoder on each column and transformed each column. Then I Converted the result into a data frame for readability. Remember that, instead of doing fit and transform at once using fit_transform, you can fit the encoder first and transform later. See below the sample code for the size column. Give it a try
# Fit and transform the 'size' column
ohe_size.fit(df[['size']])
size_encoded = ohe_size.transform(df[['size']])
size_encoded_df = pd.DataFrame(size_encoded, columns=ohe.get_feature_names_out(['size']))inverse_transform
What it does -The inverse_transform method converts the one-hot encoded binary columns back into the original categorical values.
# Convert the one-hot encoded values back to the original labels
original_colors = ohe_color.inverse_transform(color_encoded)
original_sizes = ohe_size.inverse_transform(size_encoded)
original_categories = ohe_category.inverse_transform(category_encoded)
# Display first 5 original labels
print(original_colors[:5])
print('')
print(original_sizes[:5])
print('')
print(original_categories[:5])
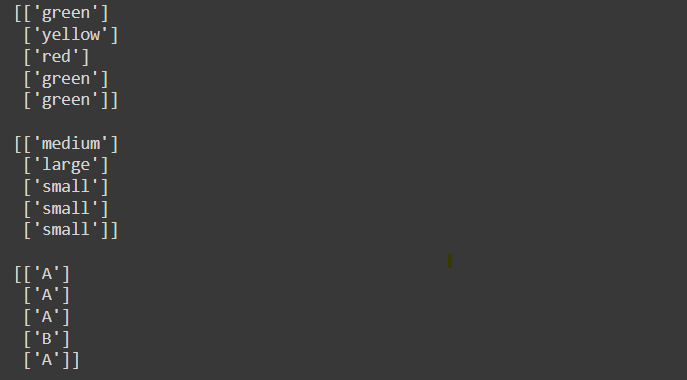
3. Using Dummy Variables with pd.get_dummies
pandas.get_dummies is a function used to convert categorical variables into dummy/indicator variables, which is a common preprocessing step in machine learning. This method creates new binary columns for each unique value in the categorical column(s).
# Create DataFrame
df = pd.DataFrame({
'color': colors,
'size': sizes,
'category': categories,
'value': values
})
# Convert categorical columns to dummy/indicator variables
dummies_df = pd.get_dummies(df, drop_first=True)
dummies_df = dummies_df.astype(int)
print(dummies_df.head())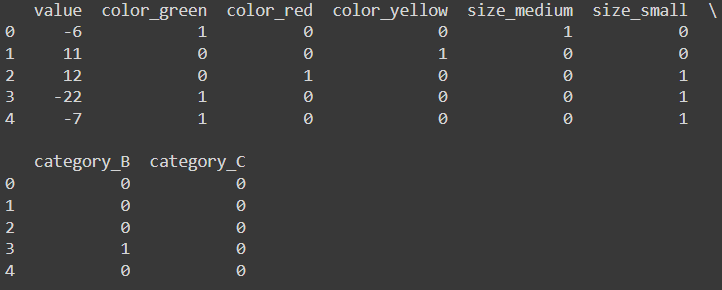
pd.get_dummies(df, drop_first=True) - This function creates dummy variables for each categorical column. The parameter drop_first=True drops the first category to avoid multicollinearity.
astype(int) - Converts the boolean values (True and False) to integers (1 and 0).
Okay, I covered three ways to turn categorical features into numerical variables. Until you get the idea, keep practicing. It will make you strong.
As a bonus section, I will give you a brief introduction to OneHotEncoder with ColumnTransfer
Understanding OneHotEncoder with ColumnTransformer
When working with machine learning, you often deal with datasets containing both categorical and numerical features. ColumnTransformer in conjunction with OneHotEncoder allows you to efficiently preprocess these different types of data.
Why Use ColumnTransformer?
- Separate Processing - It allows for applying different preprocessing techniques to different columns in the dataset.
- Efficiency - You can process multiple columns at once, ensuring that categorical features are encoded properly while numerical features are scaled or transformed as needed.
- Pipeline Integration - It integrates smoothly with Scikit-Learn pipelines, making it easier to manage and maintain data preprocessing steps.
With ColumnTransformer, you can even fill in missing values. In this example, we demonstrate how to scale the numerical value column while also handling missing values.
Let's initialize our dataset again
from sklearn.preprocessing import OneHotEncoder, StandardScaler
from sklearn.compose import ColumnTransformer
# Create DataFrame
df = pd.DataFrame({
'color': colors,
'size': sizes,
'category': categories,
'value': values
})
print(df.head())
# Create DataFrame
df = pd.DataFrame({
'color': colors,
'size': sizes,
'category': categories,
'value': values
})
print(df.head())
OneHotEncoder - Encodes categorical features into binary (0/1) format.
StandardScaler - Scales numerical features to have zero mean and unit variance.
ColumnTransformer - Allows applying different preprocessing techniques to different columns simultaneously.
# Initialize OneHotEncoder and StandardScaler
ohe = OneHotEncoder(sparse_output=False, drop='first')
scaler = StandardScaler()
# Create a ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('cat', ohe, ['color', 'size', 'category']), # Apply OneHotEncoder to categorical columns
('num', scaler, ['value']) # Apply StandardScaler to numerical column
],
remainder='passthrough' # Pass through other columns without transformation
)
# Fit and transform the data
preprocessed_data = preprocessor.fit_transform(df)
# Retrieve feature names from the fitted ColumnTransformer
# Access OneHotEncoder's feature names directly
ohe_feature_names = preprocessor.named_transformers_['cat'].get_feature_names_out(['color', 'size', 'category'])
feature_names = list(ohe_feature_names) + ['value']
# Create DataFrame with preprocessed data
preprocessed_df = pd.DataFrame(preprocessed_data, columns=feature_names)
print(preprocessed_df.head())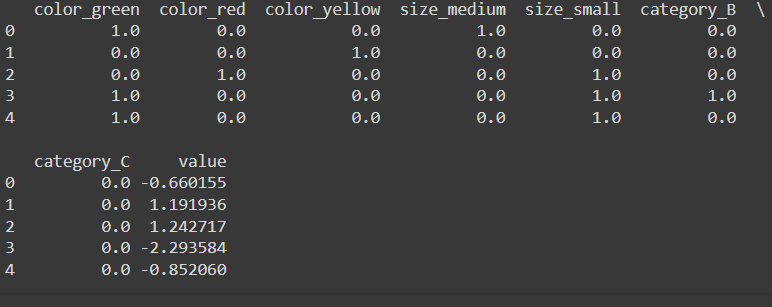
OneHotEncoder(sparse_output=False, drop='first')
sparse_output=False- Returns a dense array instead of a sparse matrix. A dense array is easier to work with for small datasets or for displaying results.StandardScaler()- Scales thevaluecolumn so that its mean is 0 and its standard deviation is 1. This helps many algorithms perform better.
ColumnTransformer - Applies transformations to different subsets of columns. In this case:
('cat', ohe, ['color', 'size', 'category'])- AppliesOneHotEncoderto the columnscolor,size, andcategory.('num', scaler, ['value'])- AppliesStandardScalerto thevaluecolumn.remainder='passthrough'- Keeps any columns not specified in the transformer list unchanged. In this case, since all columns are covered, it won't affect the output.
fit_transform - Fits the ColumnTransformer on the data and then transforms the data according to the fitted transformers. This means it learns how to encode and scale the data and then applies those transformations.
I hope you got the concepts. So remember transforming categorical data into numerical form is crucial for machine learning models to process and learn from data effectively. By using techniques such as Label Encoding, One-Hot Encoding, and Dummy Variables, you can ensure that your data is in a suitable format for various algorithms. Additionally, using tools like ColumnTransformer with OneHotEncoder and StandardScaler can streamline preprocessing by handling both categorical and numerical features efficiently.
Keep practicing these methods to enhance your data preprocessing skills and improve the performance of your machine-learning models.
If you found this article helpful, subscribe me and follow me on LinkedIn
